21. Bayesian Hierarchical Modeling#
A hands-on introduction to BHMs by looking at PyMC and Supernova Cosmology
21.1. Problem to be solved#
We want to do Bayesian Statistics (estimate model parameter PDFs given some data) but our data has some intrinsic grouping. For SN cosmology, this is often “a survey”, but it can be other data set features as well. Therfore, this is no longer a straight forward linear regression for two main reasons.
Independence of samples is an important assumption for many statistical tests, like maximum likelihood estimation.
We may want to capture the variation of the model parmeters across sub-groups.
import numpy as np
import pymc as pm
import arviz as az
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_theme(context="talk", style="ticks", font="serif", color_codes=True)
np.random.seed(0)
21.2. Exploring a Simple Hierarchical Model#
21.2.1. Model Amnesia#
Here is an example of why you might want a bit of memory in your models.
[T]he waiting time to get a cheeseburger at The Tavern to the Golden M in Germany takes two minutes on average (I made up this number). If I go to France now, chances are that the average waiting time is not too far off from these two minutes. And probably the same goes for Japan. Sure, some countries are faster, and some are slower on average, but waiting for a cheeseburger for an hour should be a somewhat rare exception, regardless of the country. So, if I am hungry and want a cheeseburger in France, I have an expectation of how long I have to wait, and I will probably be kind of right. I can transfer knowledge learned from one group (Germany) to make predictions for another group (France).
Dr. Robert Kübler, “Bayesian Hierarchical Modeling in PyMC3”
Three options to predict how long it will take to make a cheeseburger.
Maybe this should just be one model that marginalizes over the country (fully pooled).
Germany, France, and Japan can all be different models with no relationship across countries (unpooled).
Finally, you can fit for both the per-country cheeseburger rate, along with the planetary average that influences the priors of the per-country rate (BHM).
21.2.2. Building a mock dataset#
Let’s make a data set of 8 sub-sets. This is a 1D model fit: one x (feature) and one y (target). The truth values in this data set are that there are 8 individual slopes, one per subgroup, and all have a fixed intercept of zero.
mean_slope = 2
# the 8 different slopes have a mean of 2 and sigma of 1
slopes = np.random.normal(mean_slope, size=8)
# group "7" is smaller than all other groups.
groups = np.array(50*[0, 1, 2, 3, 4, 5, 6] + 5*[7])
x_obs = np.random.randn(355)
# y_obs has noise at the level of 0.1 compared to the "true" value of `slopes[groups] * x`
y_obs = slopes[groups] * x_obs + 0.1*np.random.randn(355)
# Lets look at our slopes, since 8 is a small sample set.
print(slopes)
print(np.mean(slopes))
[1.8672689 3.14148115 2.98165906 0.62435472 1.26688805 3.91300139
0.67082731 1.01325524]
1.934841978026419
# all of group 2 can be found via
print(f'{x_obs[groups==2]=}')
print(f'{y_obs[groups==2]=}')
print(f'{slopes[2]=}')
x_obs[groups==2]=array([ 0.12160602, 0.15574161, -0.94480271, -0.21687516, 0.98308489,
0.27238398, 0.22177082, -1.00269028, -1.06604604, -1.35079969,
-4.01968523, 0.29913263, -0.10171202, -0.89426151, 0.90878906,
-0.07264521, 0.34711157, 0.55861271, 0.22407761, -0.1625908 ,
-0.69652135, 1.02780299, 0.89996977, -0.56192199, 0.9713535 ,
0.54579941, 0.5075971 , -0.15055574, 1.11695141, -0.02094534,
-0.09656938, 0.36230428, -1.32302996, 1.69146854, -2.10293005,
-0.48289206, -0.79422421, 1.11426178, -1.75892487, 0.37705734,
-1.87935716, 0.10202381, 0.88651762, -1.21497734, -0.99201342,
0.99877274, 0.0641854 , 0.02618433, 0.06848467, -0.01303212])
y_obs[groups==2]=array([ 4.46525536e-01, 5.43182822e-01, -2.83623125e+00, -6.87643495e-01,
2.80422537e+00, 8.07782923e-01, 6.85714185e-01, -2.96427863e+00,
-3.18337021e+00, -4.06148682e+00, -1.19630151e+01, 8.88728683e-01,
-1.35759320e-01, -2.47840083e+00, 2.69354410e+00, -2.28971114e-01,
9.41711668e-01, 1.74628440e+00, 6.40583023e-01, -5.02891881e-01,
-2.14807128e+00, 2.98277802e+00, 2.77668518e+00, -1.57117399e+00,
2.71613186e+00, 1.50925452e+00, 1.48468174e+00, -5.18210528e-01,
3.32820836e+00, -4.59411372e-02, -1.85884282e-01, 1.07063190e+00,
-3.95641270e+00, 4.99578894e+00, -6.27612794e+00, -1.60391553e+00,
-2.41240662e+00, 3.28482384e+00, -5.32859537e+00, 1.23257318e+00,
-5.59506057e+00, 3.09220261e-01, 2.71323931e+00, -3.59579882e+00,
-2.84150248e+00, 2.95162652e+00, 2.28173229e-01, 7.82886573e-02,
3.02295626e-01, -4.27881470e-03])
slopes[2]=2.9816590595896724
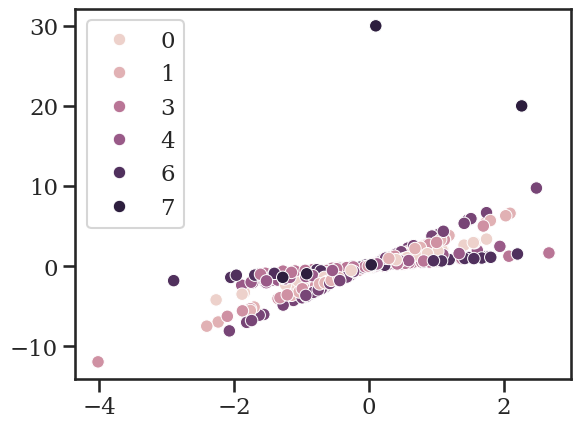
Now we will add two outliers the small “group 7”.
y_obs[-1] = 30
y_obs[-2] = 20
plt.figure()
sns.scatterplot(x=x_obs, y=y_obs, hue=groups)
<Axes: >
21.2.3. Fitting Slopes With a Pooled Model#
Along with an introduciton to pymc3.
# model is y = m*x + noise
# build a model via a `with` context block.
with pm.Model() as pooled_model:
# define priors on single slope and the added noise
slope = pm.Normal('slope', 0, 20)
noise = pm.Exponential('noise', 0.1)
# define observations: y_obs = slope * x_obs + noise.
# link variables to data with `observed=y`
obs = pm.Normal('obs', slope*x_obs, noise, observed=y_obs)
# run sampler
pooled_trace = pm.sample()#return_inferencedata=True)
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [slope, noise]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 0 seconds.
az.plot_posterior(pooled_trace, var_names=['slope'])
<Axes: title={'center': 'slope'}>
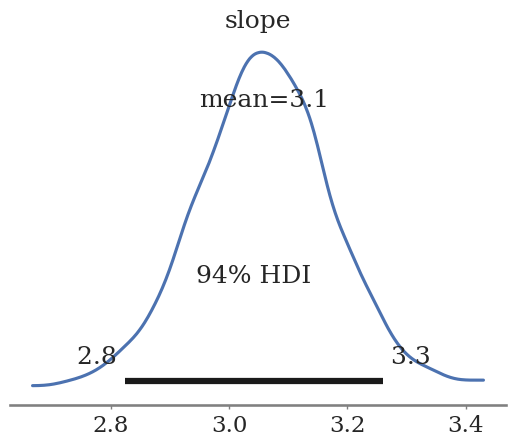
The slope here is \(3.1 \pm 0.2\). This is not exactly 2.9.
21.2.4. Fitting Slopes With an Unpooled Model#
This is eight different slopes that have no knowledge of each other.
with pm.Model() as unpooled_model:
slope = pm.Normal('slope', 0, 20, shape=8)
noise = pm.Exponential('noise', 10)
obs = pm.Normal('obs', slope[groups]*x_obs, noise, observed=y_obs)
unpooled_trace = pm.sample(return_inferencedata=True)
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [slope, noise]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 1 seconds.
az.plot_posterior(unpooled_trace, var_names=['slope'])
az.plot_forest(unpooled_trace, var_names=['slope'], combined=True)
array([<Axes: title={'center': '94.0% HDI'}>], dtype=object)
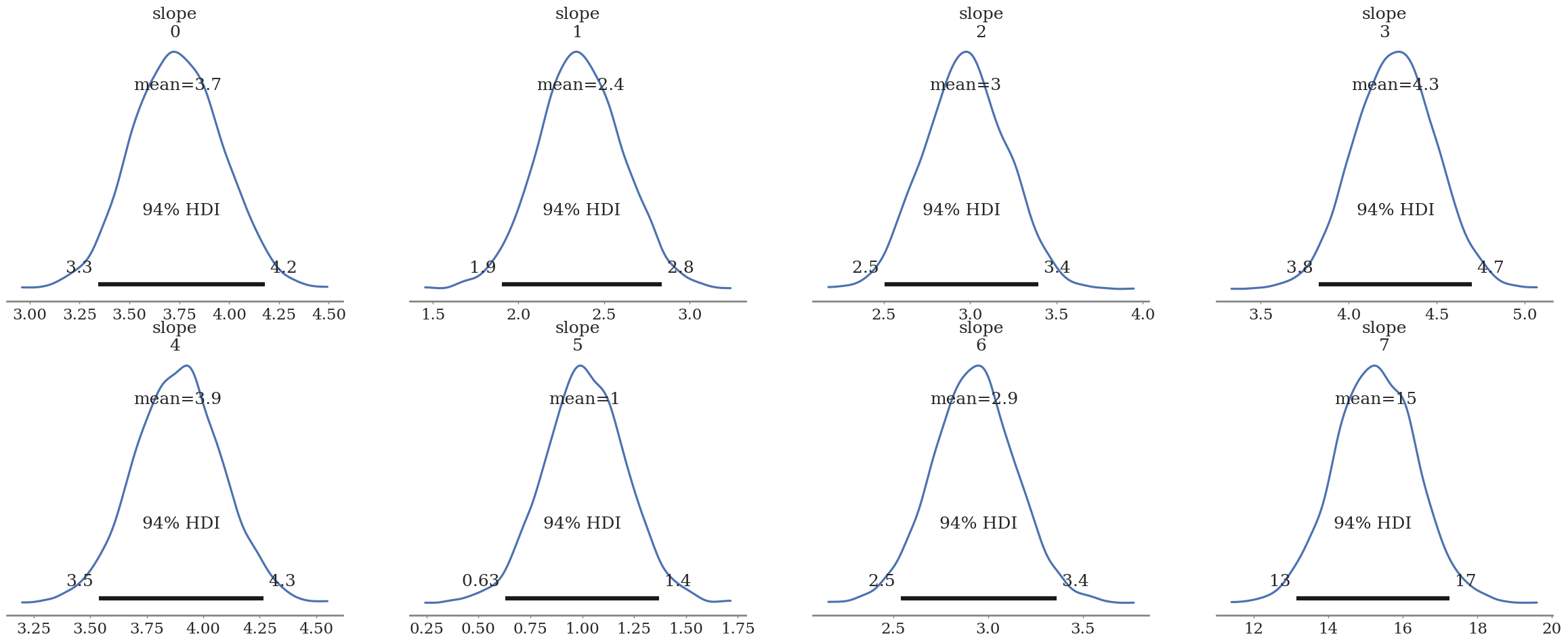
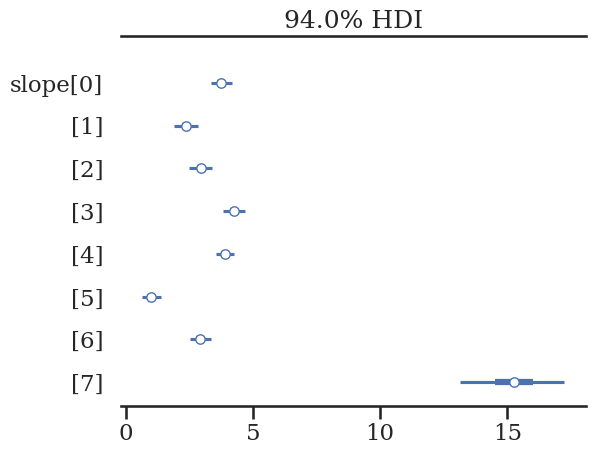
Group 7 should be 1.8! Let’s use the other subgroups to improve our estimate of the true value for “group 7”.
In hierarchical modeling, all parameters are being pulled towards a global mean. This effect is known as shrinkage.
Dr. Robert Kübler, “Bayesian Hierarchical Modeling in PyMC3”
21.2.5. Example of a BHM#
We want to find a middle ground that finds a compromise between these extremes — partial pooling. This brings us to Bayesian hierarchical modeling, also known as multilevel modeling.
Surya Krishnamurthy, “Introduction to hierarchical modeling”
with pm.Model() as hierarchical_model:
# now you need "hyperpriors" to provide information to transfer between sub-models
# mu_slope is the global average
# simga_slope is the strength of the information transfer
# sigma_slope = 0 is pooled. simga_slope = inf is unpooled. BHM is in the middle.
mu_slope = pm.Normal('mu_slope', 0, 1) # hyperprior 1
sigma_slope = pm.Exponential('sigma_slope', 13) # hyperprior 2
# Same "priors" as `unpooled_model`
#but now `mu_slope` and `sigma_slope` are variables and not values
slope = pm.Normal('slope', mu_slope, sigma_slope, shape=8)
noise = pm.Exponential('noise', 10)
obs = pm.Normal('obs', slope[groups]*x_obs, noise, observed=y_obs)
# Note that we ended up adjusting how the sampler worked (`target_accept=0.995`)
# This model has the most parameters (and correlations), so it can become hard to converve
hierarchical_trace = pm.sample(
return_inferencedata=True,
target_accept=0.995
)
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [mu_slope, sigma_slope, slope, noise]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 3 seconds.
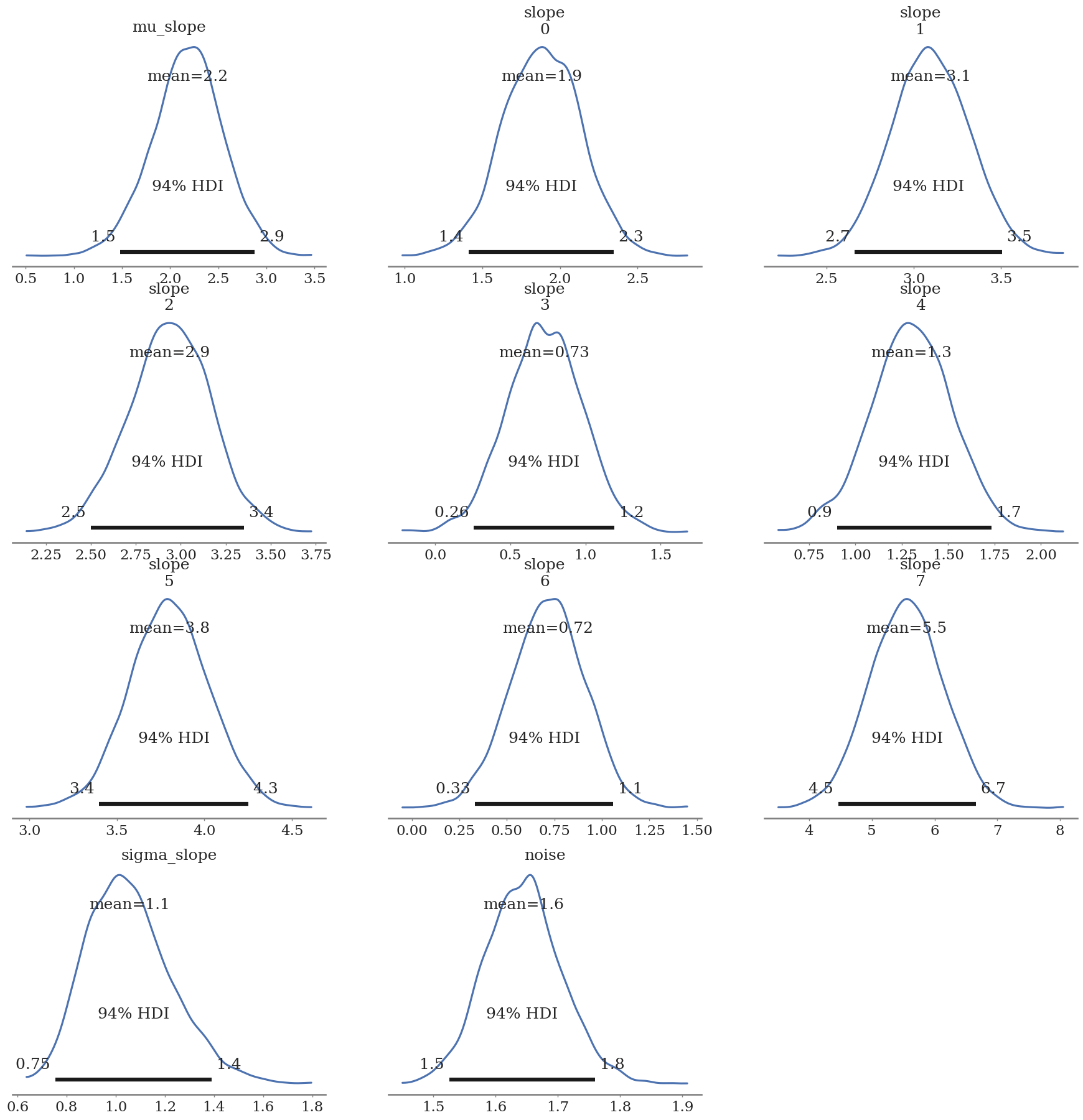
az.plot_posterior(hierarchical_trace)
az.plot_forest(hierarchical_trace, var_names=['slope'], combined=True)
array([<Axes: title={'center': '94.0% HDI'}>], dtype=object)
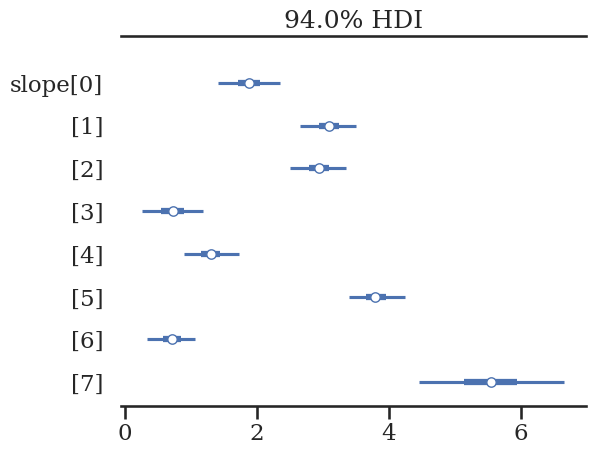
Group 7 is still dominated by the 40% outliers, but this is much closer to the true values that were used to build the dataset.
21.3. Visually Describing Models#
“Plate notation” is a method of representing variables, their relationships, and how they repeat (think vector vs matrix vs scalar) in a graphical form. We typically use a tool and standard called Graphviz to do this.
pm.model_to_graphviz(pooled_model)

pm.model_to_graphviz(unpooled_model)

pm.model_to_graphviz(hierarchical_model)

21.4. BHMs in SN Cosmology#
There are two common BHMs in SN cosmology: BayeSN and UNITY. BayeSN goes from photometry to light-curve parameters and UNITY goes from light-curve parameters to cosmology. Both groups are working towards a grand photometry-to-cosmology model.
Let’s look at the UNITY model diagram and try to understand this model:
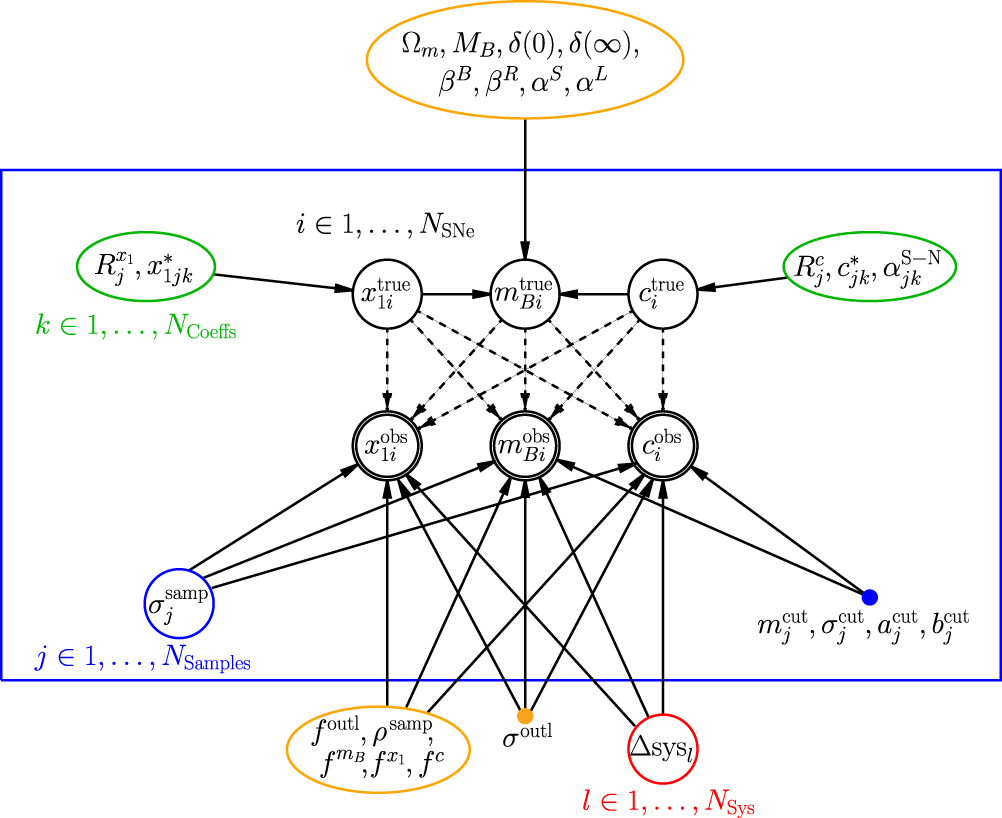
Figure Caption: Probabilistic Graphical Model of our framework showing the causal links. An edge from one node (e.g., Ωm) to another (e.g., m^true_B_i) means that the latter is conditional upon the former (e.g., m^true_Bi is conditional on Ωm). The enclosed nodes represent variables that are sampled in the MCMC. Global parameters are in orange nodes (single parameters) and red nodes (the set of systematic uncertainty parameters). Green nodes enclose the hyperparameters (parameters of a prior distribution) of the latent-variable priors, and the singly outlined black nodes show those latent variables. Blue nodes show sample-dependent quantities. Finally, the outlined nodes show the observed light-curve fits. (Each of {m^obs_Bi,x^obs_1i,c^obs_i} depends on {m^true_Bi,x^true_1i,c^true_i} as the light-curve fit and unexplained dispersion have correlated uncertainties.) i ranges over each SN, j ranges over each SN sample, k ranges over the coefficients in redshift within a sample, and l ranges over each systematic uncertainty (e.g., calibration). Note that the m^true_Bi are completely determined by other parameters and are not true fit parameters. We fix the selection effect parameters, m^cut_j, σ^cut_j, a^cut_j, b^cut_j, and the outlier distribution width σ^out_l, so these are represented filled nodes.
Aside: On my soapbox, I’ll take my time to say how with a BHM, for intermediate steps (like population models) you just need an approximately good prior and you can marginalize over your uncertainties. Additionally, every variable is treated like a PDF, so point estimates or complex multi-modal PDFs are the same—at least mathematically even if they are not the same for sampling.
21.5. Conclusion#
BHMs allow for a unique situation where you can model weak depenacnes of realted subgroups in a Bayesian framework. This is an important tool in improving the descriptive power of your models without changing to a more complicated mathematical realtionship. In this docuement, we were only fits slopes, but we were able to look at the variation of slopes as a function of subgroups. This sounds a lot like the varition of \(R_V\) populations as a function of host galaxy types/sizes.
21.6. Further Reading#
%load_ext watermark
%watermark -untzvm -iv -w
Last updated: Thu Apr 17 2025 11:35:21CDT
Python implementation: CPython
Python version : 3.11.12
IPython version : 9.1.0
Compiler : Clang 18.1.8
OS : Darwin
Release : 24.4.0
Machine : arm64
Processor : arm
CPU cores : 12
Architecture: 64bit
pandas : 2.2.3
rich : 14.0.0
pymc : 5.22.0
seaborn : 0.13.2
arviz : 0.21.0
numpy : 1.25.2
matplotlib: 3.10.1
Watermark: 2.5.0